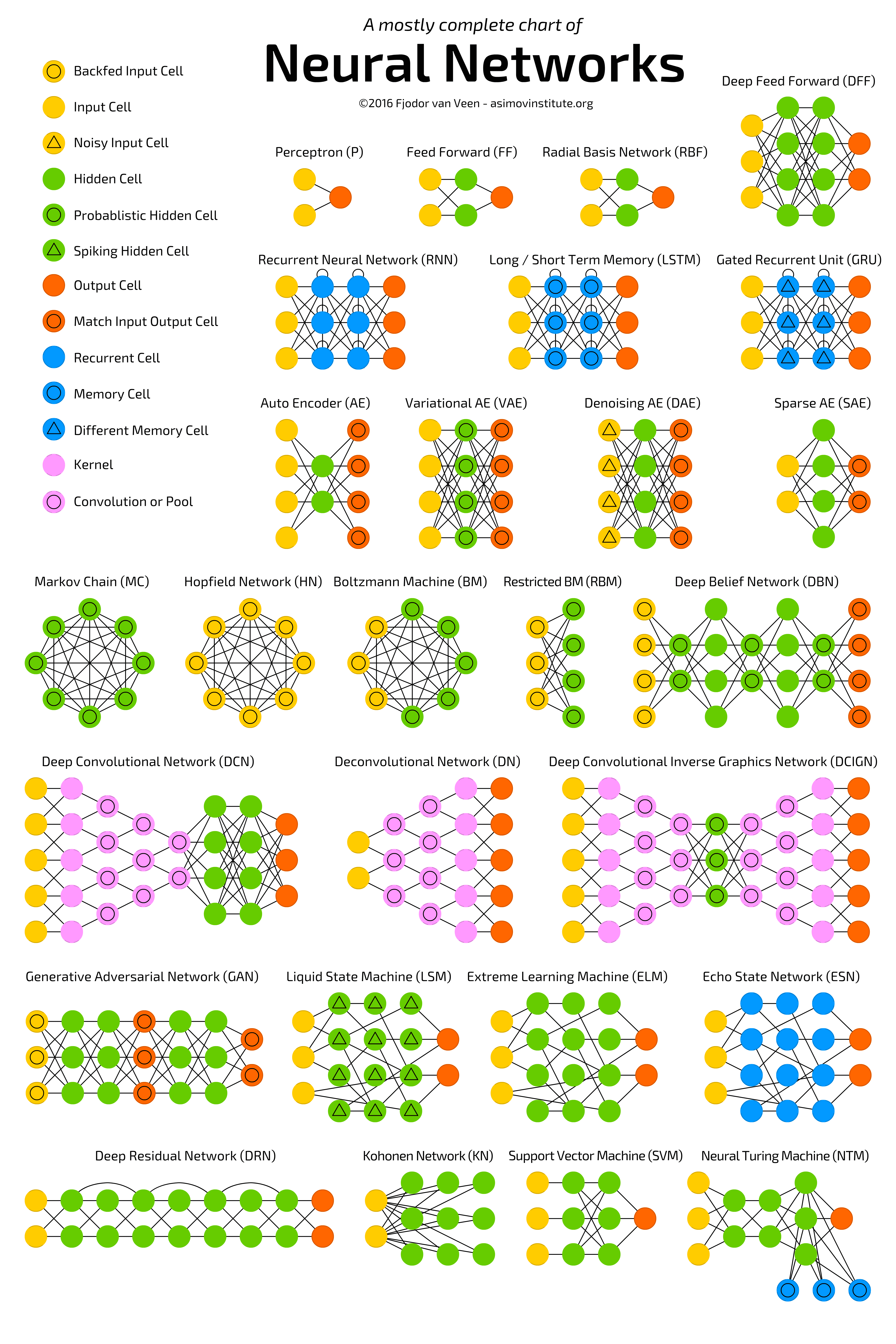
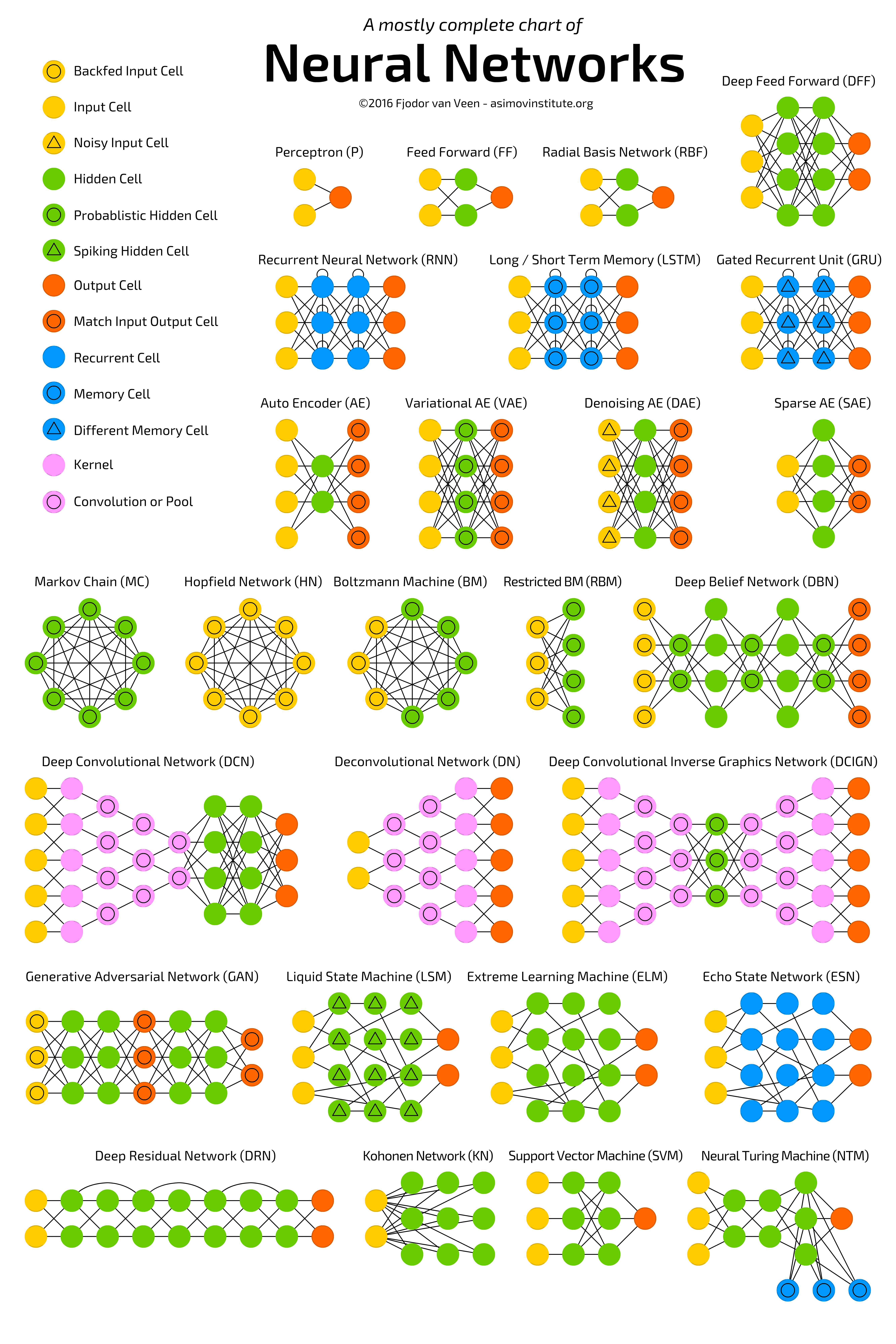
Neural network architectures form the backbone of modern machine learning, offering versatile solutions to diverse challenges. From foundational models like Perceptron and Feedforward Neural Networks to cutting-edge designs such as Capsule Networks and Attention Mechanisms, these structures power applications in image recognition, natural language processing, and more. Memory-augmented models like Differentiable Neural Computers (DNCs) and Self-Organizing Maps (SOMs) enable advanced reasoning, while attention networks revolutionize contextual processing. As we explore these architectures, each with its own unique strengths, we uncover the evolving landscape shaping the future of artificial intelligence. The array of neural network types is expanding rapidly, requiring a guide to navigate through numerous emerging architectures and methodologies. If you're familiar with machine learning, chances are you've come across it already.
Perceptron (P)
The perceptron is the simplest form of a neural network and serves as the fundamental building block of more complex neural network architectures. It was developed by Frank Rosenblatt in 1957. The perceptron is limited to linearly separable problems, which means it can only learn to classify patterns that can be separated by a hyperplane in the input space. However, it paved the way for more sophisticated neural network architectures that can handle more complex tasks
Feed Forward (FF)
Feed forward in neural networks refers to the flow of information through the network, starting from the input layer, passing through one or more hidden layers, and finally producing an output. It's a fundamental aspect of how neural networks process information. A feed-forward neural network, also known as a multilayer perceptron (MLP), is one of the most common architectures in artificial neural networks.
Radial Basis Network (RBF)
A Radial Basis Function (RBF) network is a type of artificial neural network that uses radial basis functions as activation functions. It consists of three layers: an input layer, a hidden layer with radial basis functions, and an output layer. Input Layer: This layer represents the input features of the network. Each node in this layer corresponds to a feature of the input data. Hidden Layer: The hidden layer of an RBF network uses radial basis functions as activation functions. Output Layer: The output layer produces the final output of the network. The output is typically a linear combination of the activations of the nodes in the hidden layer.
Deep Feed Forward (DFF)
"Deep Feedforward" refers to a type of neural network architecture with multiple hidden layers, commonly known as a deep neural network. This contrasts with a shallow architecture, like a standard feed-forward neural network with only one or two hidden layers. The terms "deep feed forward" and "deep neural network" are often used interchangeably.
Recurrent Neural Network (RNN)
Recurrent Neural Network (RNN) is a type of neural network designed for sequential data processing and tasks where the order of the input data is important. Unlike traditional feed forward neural networks, RNNs have connections that form directed cycles, allowing them to maintain a hidden state representing information from previous time steps.
Long/Short Term Memory (LSTM)
Long Short-Term Memory (LSTM) is a type of recurrent neural network (RNN) architecture designed to overcome some of the limitations of traditional RNNs in learning long-term dependencies. LSTMs were introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997. They have proven to be highly effective in tasks involving sequential data, such as natural language processing, speech recognition, and time series analysis.
Gated Recurrent Unit (GRU)
Gated Recurrent Unit (GRU) is a type of recurrent neural network (RNN) architecture, similar to the Long Short-Term Memory (LSTM) network. Both GRU and LSTM were designed to address the challenges of learning long-term dependencies in sequential data, and they share certain characteristics. GRUs were introduced by Kyunghyun Cho et al. in 2014 as a more simplified version of LSTMs.
Auto Encoder (AE)
Autoencoder (AE) is a type of artificial neural network used for unsupervised learning. Its primary objective is to learn a representation (encoding) of input data in a way that captures essential features. Autoencoders consist of an encoder and a decoder, and they are often employed for tasks such as dimensionality reduction, feature learning, and data generation.
Variational AE (VAE)
Variational Autoencoder (VAE) is a type of autoencoder that introduces probabilistic elements to the encoding and decoding processes. VAEs are a specific class of generative models that not only learn a compressed representation of input data but also generate new samples by sampling from a probabilistic distribution in the latent space. VAEs were introduced by Kingma and Welling in 2013.
Denoising AE (DAE)
Denoising Autoencoder (DAE) is a type of autoencoder designed to learn robust representations of input data by training on noisy or corrupted versions of that data. The primary objective of a Denoising Autoencoder is to reconstruct the original, uncorrupted input from its noisy counterpart. DAEs are commonly used for tasks such as feature learning, data denoising, and dimensionality reduction.
Sparse AE (SAE)
Sparse Autoencoder (SAE) is a type of autoencoder that incorporates a sparsity constraint during training. The primary goal of a Sparse Autoencoder is to learn a compact representation of input data while promoting sparsity in the learned features. Sparsity encourages the autoencoder to activate only a subset of neurons in the hidden layer for a given input, leading to more efficient and selective feature learning.
Markov Chain (MC)
Markov Chain (MC) is a mathematical model used to describe a sequence of events in which the probability of transitioning to any particular state depends solely on the current state and time elapsed, regardless of how the system arrived at its current state. In other words, it exhibits the Markov property, which is the memoryless property that the future state depends only on the present state and not on the sequence of events that preceded it.
Hopfield Network (HN)
Hopfield Network (HN) is a type of recurrent artificial neural network invented by John Hopfield in 1982. It is an associative memory network that is designed to store and retrieve patterns. Hopfield networks are commonly used for pattern recognition, optimization, and content-addressable memory.
Boltzmann Machine (BM)
Boltzmann Machine (BM) is a type of stochastic, recurrent neural network that can be used for learning and representing probability distributions over its set of binary-valued units. Boltzmann Machines were introduced by Geoffrey Hinton and Terry Sejnowski in the 1980s. They belong to the broader family of energy-based models and share similarities with Hopfield Networks, but they extend the concept to a more complex and probabilistic framework.
Restricted BM (RBM)
Restricted Boltzmann Machine (RBM) is a type of generative stochastic artificial neural network with a bipartite graph structure. Introduced by Geoffrey Hinton and collaborators in the mid-2000s, RBMs are simpler versions of Boltzmann Machines, specifically designed to be more computationally efficient and tractable for training.
Deep Belief Network (DBN)
Deep Belief Network (DBN) is a type of generative deep learning model composed of multiple layers of stochastic, latent variables. Introduced by Geoffrey Hinton and his collaborators in the mid-2000s, DBNs are probabilistic models that consist of multiple layers of Restricted Boltzmann Machines (RBMs).
Deep Convolutional Network (DCN)
It seems like there might be a slight error in the term you provided. I'll assume you are referring to a "Deep Convolutional Network" or "Convolutional Neural Network (CNN)," which is a widely used architecture in deep learning, especially for image-related tasks.
A Deep Convolutional Network (DCN) is essentially synonymous with Convolutional Neural Network (CNN), so I'll provide information about CNNs.
A Convolutional Neural Network (CNN) is a type of artificial neural network that has proven to be highly effective in tasks related to computer vision, particularly image classification and object recognition. CNNs are designed to automatically and adaptively learn hierarchical representations of data through the use of convolutional layers.
Deconvolutional Network (DN)
Deconvolutional Network (DN) might be a bit misleading. It's more commonly referred to as a "Deconvolutional Neural Network" or "Transposed Convolutional Network." Another term used for the operation involved is "Fractionally Strided Convolution" or "Transpose Convolution."
A Transposed Convolutional Neural Network (Transposed ConvNet or DeconvNet) is a type of neural network architecture that involves the use of transposed convolutions or fractionally strided convolutions. These operations are essentially the reverse of the standard convolutional operations used in Convolutional Neural Networks (CNNs). While the term "deconvolution" is often used colloquially, it's important to note that the operation involved is not a true deconvolution in the mathematical sense.
Deep convolutional Inverse Graphics Network (DCIGN)
This typically refers to Convolutional Neural Networks (CNNs) with multiple layers, which are widely used in computer vision tasks for tasks such as image classification, object detection, and segmentation. Inverse Graphics: In the context of computer vision and image processing, inverse graphics generally refers to the idea of inferring the underlying 3D scene or properties from 2D images. This involves understanding the processes that generated the observed images.
Generative Adversarial Network (GAN)
Generative Adversarial Network (GAN) is a class of artificial intelligence algorithms used in unsupervised machine learning. GANs were introduced by Ian Goodfellow and his colleagues in 2014 and have since become a popular and powerful approach for generating realistic and high-quality synthetic data. The key idea behind GANs is to train two neural networks, a generator, and a discriminator, in a competitive manner. The generator tries to produce data that is indistinguishable from real data, while the discriminator aims to differentiate between real and generated data. This adversarial training process results in the generator continuously improving its ability to generate realistic data, and the discriminator improving its ability to distinguish between real and generated data.
Liquid State Machine (LSM)
Liquid State Machine (LSM) is a type of recurrent neural network (RNN) that is inspired by the dynamics of the brain's cortical microcircuits. It was introduced by Wolfgang Maass and his collaborators in the early 2000s. The LSM is a specific form of reservoir computing, a paradigm within neural networks where a dynamic system, called the reservoir, is used to process input data, and a readout layer is trained to perform a desired task.
Extreme Learning Machine (ELM)
Extreme Learning Machine (ELM) is a type of machine learning algorithm that belongs to the family of feedforward neural networks. It was proposed by Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew in 2006. ELM is known for its simplicity, efficiency, and fast training speed compared to traditional neural network training algorithms.
Echo State Network (ESN)
Echo State Network (ESN) is a type of recurrent neural network (RNN) designed for efficient processing of temporal information and sequential data. ESNs were introduced by Jaeger and Haasdonk in 2004. They belong to the family of reservoir computing models, similar to Liquid State Machines (LSMs)
Deep Residual Network (DRN)
Deep Residual Network (DRN) is a type of neural network architecture designed to address the challenge of training very deep networks. Deep Residual Networks were introduced by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun in their paper titled "Deep Residual Learning for Image Recognition" in 2016. DRNs are particularly known for their use of residual blocks, which contain shortcut connections that skip one or more layers.
Differentiable Neural Computer (DNC)
Differentiable Neural Computer (DNC) is a type of neural network architecture that combines neural networks with an external memory matrix, allowing the model to store and retrieve information in a way that resembles the memory functions of a computer. It was introduced by Alex Graves, Greg Wayne, and Ivo Danihelka in a paper titled "Neural Turing Machines" in 2014 and further developed in subsequent works. DNCs are particularly well-suited for tasks where the ability to store and recall information over long sequences is crucial. They showcase the potential of combining neural networks with external memory to achieve more sophisticated and flexible forms of computation.
Neural Turing Machine (NTM)
Neural Turing Machine (NTM) is a type of neural network architecture designed to mimic the working principles of a Turing machine, a theoretical model of computation that can simulate any algorithm. NTMs were introduced by Alex Graves, Greg Wayne, and Ivo Danihelka in their 2014 paper titled Neural Turing Machines. t bridges the gap between traditional computation models and neural network-based approaches, enabling neural networks to perform more complex and algorithmic tasks. NTMs and related architectures, such as Differentiable Neural Computers (DNCs), have opened up new possibilities for developing intelligent systems capable of more sophisticated reasoning and learning.
Capsule Network (CN)
Capsule Network (CapsNet or CN) is a type of neural network architecture introduced by Geoffrey Hinton and his colleagues in the paper titled "Dynamic Routing Between Capsules" in 2017. Capsule Networks are designed to address some of the limitations of traditional Convolutional Neural Networks (CNNs) in handling hierarchical relationships and viewpoint variations in visual data. Capsule Networks represent an innovative approach to addressing issues related to hierarchical feature learning and viewpoint variations in image data.
Kohonen Network (KN)
Kohonen Network, also known as a Self-Organizing Map (SOM) or Kohonen Self-Organizing Map (KSOM), is a type of artificial neural network that belongs to the category of unsupervised learning models. It was introduced by Teuvo Kohonen in the 1980s. It have been widely used for tasks where the structure and relationships within the data are important. Their ability to organize input patterns in a topological manner makes them valuable for exploratory data analysis and representation learning.
Attention Network (AN)
Attention Network, or Attention Mechanism, is a component used in neural network architectures to selectively focus on different parts of the input data, assigning varying degrees of importance to different elements. Attention mechanisms have become a fundamental building block in many state-of-the-art neural network models, particularly in natural language processing (NLP) and computer vision tasks.
Trending Posts
-
 What is the significance of digital marketing to building a brand?
06-04-2023
What is the significance of digital marketing to building a brand?
06-04-2023
-
 The Power of generative adversarial networks (GANs)
11-10-2023
The Power of generative adversarial networks (GANs)
11-10-2023
-
 Difference between Manual vs Computerized Accounts
26-10-2023
Difference between Manual vs Computerized Accounts
26-10-2023
-
 Concept of Object-Oriented Programming in java with Examples - oops
26-10-2023
Concept of Object-Oriented Programming in java with Examples - oops
26-10-2023
-
 Importance of Data Visualization in Data Science
27-10-2023
Importance of Data Visualization in Data Science
27-10-2023
-
 Introduction to Exception handling in java and types of Exceptions
01-11-2023
Introduction to Exception handling in java and types of Exceptions
01-11-2023
-
 Difference between Packages and Modules in python
01-11-2023
Difference between Packages and Modules in python
01-11-2023
-
 Workers in India need to be upskilled, reskilled in AI, automation
02-11-2023
Workers in India need to be upskilled, reskilled in AI, automation
02-11-2023
-
 Challenges in equipping job seekers with skills
02-11-2023
Challenges in equipping job seekers with skills
02-11-2023
-
 Control Structures in Python with examples. Condition Statements, loop and Control Flow Statements
04-11-2023
Control Structures in Python with examples. Condition Statements, loop and Control Flow Statements
04-11-2023
-
 Music can help learners improve their skills.
08-11-2023
Music can help learners improve their skills.
08-11-2023
-
 Data Structures And Algorithms In Python - Basic To Advanced Level
18-11-2023
Data Structures And Algorithms In Python - Basic To Advanced Level
18-11-2023
-
 An Introduction to nlp Natural Language Processing
22-11-2023
An Introduction to nlp Natural Language Processing
22-11-2023
-
 internship for computer science students
23-11-2023
internship for computer science students
23-11-2023
-
 The Impact of Predictive Analytics in Healthcare
30-11-2023
The Impact of Predictive Analytics in Healthcare
30-11-2023
-
 Guidelines for Protecting Removable Media
02-12-2023
Guidelines for Protecting Removable Media
02-12-2023
-
 What are Social Engineering Attacks? Common Techniques Used in Social Engineering Attacks
04-12-2023
What are Social Engineering Attacks? Common Techniques Used in Social Engineering Attacks
04-12-2023
-
 Importance of Search Engine Optimization and its Techniques
06-12-2023
Importance of Search Engine Optimization and its Techniques
06-12-2023
-
 Understanding AWS Buckets: The Essential Guide to Cloud Storage
11-12-2023
Understanding AWS Buckets: The Essential Guide to Cloud Storage
11-12-2023
-
 What is sem marketing? search engine marketing
12-12-2023
What is sem marketing? search engine marketing
12-12-2023
-
 What is SMM in Digital Marketing? Social Media Marketing
13-12-2023
What is SMM in Digital Marketing? Social Media Marketing
13-12-2023
-
 A Comprehensive Guide to Ensuring Security with Amazon EC2
15-12-2023
A Comprehensive Guide to Ensuring Security with Amazon EC2
15-12-2023
-
 Understanding Azure Storage Services - A Comprehensive Overview
19-12-2023
Understanding Azure Storage Services - A Comprehensive Overview
19-12-2023
-
 Mastering Azure App Services - Ultimate Toolkit for Success in Your Azure Course in Vizag
21-12-2023
Mastering Azure App Services - Ultimate Toolkit for Success in Your Azure Course in Vizag
21-12-2023
-
 An In-depth Exploration of Arrays in C
27-12-2023
An In-depth Exploration of Arrays in C
27-12-2023
-
 A Journey into AI Projects and Their Transformative Influence on the Contemporary World
27-12-2023
A Journey into AI Projects and Their Transformative Influence on the Contemporary World
27-12-2023
-
 Facebook Ads Webinar
27-12-2023
Facebook Ads Webinar
27-12-2023
-
 pricing models, cost efficiency and resource optimization techniques of Azure App Services
28-12-2023
pricing models, cost efficiency and resource optimization techniques of Azure App Services
28-12-2023
-
 Navigating the Cloud - An In-Depth Amazon VPC Overview
29-12-2023
Navigating the Cloud - An In-Depth Amazon VPC Overview
29-12-2023
-
 Demystifying Cloud Deployment Models: Choosing the Right Strategy for Your Business
30-12-2023
Demystifying Cloud Deployment Models: Choosing the Right Strategy for Your Business
30-12-2023
-
 A Comprehensive Guide to Basic Excel Formulas
01-01-2024
A Comprehensive Guide to Basic Excel Formulas
01-01-2024
-
 Unleashing the Power of Excel Search Functions Stream Data Analysis
02-01-2024
Unleashing the Power of Excel Search Functions Stream Data Analysis
02-01-2024
-
 Mastering Validations in Microsoft Excel: A Comprehensive Guide
03-01-2024
Mastering Validations in Microsoft Excel: A Comprehensive Guide
03-01-2024
-
 Mastering Structures in C: Understanding, Implementation, and Best Practices
04-01-2024
Mastering Structures in C: Understanding, Implementation, and Best Practices
04-01-2024
-
 C Union and benefits of using C unions in programming
05-01-2024
C Union and benefits of using C unions in programming
05-01-2024
-
 What are Microsoft Word Macros and How to Use Them?
08-01-2024
What are Microsoft Word Macros and How to Use Them?
08-01-2024
-
 Making Your Document Look Professional in ms word - Page Layout, Margins, Orientation and Size
10-01-2024
Making Your Document Look Professional in ms word - Page Layout, Margins, Orientation and Size
10-01-2024
-
 The Rise of blockchain Projects: Unveiling the Innovations of Shaping Digital Landscape
11-01-2024
The Rise of blockchain Projects: Unveiling the Innovations of Shaping Digital Landscape
11-01-2024
-
 Comprehensive Guide of Neural Network Architectures
11-01-2024
Comprehensive Guide of Neural Network Architectures
11-01-2024
-
 The Future is Here: How Blockchain Technology is Reshaping Industries and Redefining Trust
12-01-2024
The Future is Here: How Blockchain Technology is Reshaping Industries and Redefining Trust
12-01-2024
-
 powerpoint presentation-Page Transitions: Enhancing Navigation and User Experience
17-01-2024
powerpoint presentation-Page Transitions: Enhancing Navigation and User Experience
17-01-2024
-
 Exploring the Power of Multimedia in PowerPoint Presentations
18-01-2024
Exploring the Power of Multimedia in PowerPoint Presentations
18-01-2024
-
 Mastering Photoshop Layers: A Comprehensive Guide to Professional Results
19-01-2024
Mastering Photoshop Layers: A Comprehensive Guide to Professional Results
19-01-2024
-
 Enhance Your Photoshop Skills with Expert Selection Techniques
20-01-2024
Enhance Your Photoshop Skills with Expert Selection Techniques
20-01-2024
-
 Life and Work on a Cruise Ship - What to Expect?
22-01-2024
Life and Work on a Cruise Ship - What to Expect?
22-01-2024
-
 Mastering Photoshop Masks: A Step-by-Step Guide to Enhance Your Photo Editing Skills
23-01-2024
Mastering Photoshop Masks: A Step-by-Step Guide to Enhance Your Photo Editing Skills
23-01-2024
-
 Enhance Your Digital Artistry with the Top Photoshop Brushes for Every Style and Project
27-01-2024
Enhance Your Digital Artistry with the Top Photoshop Brushes for Every Style and Project
27-01-2024
-
 The reason behind the success of Milan 2024
26-02-2024
The reason behind the success of Milan 2024
26-02-2024
-
 Visakhapatnam is witnessing comprehensive growth across all sectors!
06-03-2024
Visakhapatnam is witnessing comprehensive growth across all sectors!
06-03-2024
-
 Vizag's Journey Towards Becoming a Global IT Destination
12-03-2024
Vizag's Journey Towards Becoming a Global IT Destination
12-03-2024
-
 the best software courses after the 10th/Intermediate exams for Students
02-04-2024
the best software courses after the 10th/Intermediate exams for Students
02-04-2024
-
 2024's Tech Frontier: A Deep Dive into Software Development Trends
16-04-2024
2024's Tech Frontier: A Deep Dive into Software Development Trends
16-04-2024
-
 4 Important benefits for Continuous Learning in Tech
07-05-2024
4 Important benefits for Continuous Learning in Tech
07-05-2024
-
 A Beginner's Guide to AWS, Azure, and Google Cloud Platform
14-05-2024
A Beginner's Guide to AWS, Azure, and Google Cloud Platform
14-05-2024
-
 Why Full Stack Python is a Must-Learn Skill for Aspiring Developers?
12-09-2024
Why Full Stack Python is a Must-Learn Skill for Aspiring Developers?
12-09-2024
-
 What’s Next? The Future of Asteroid Tracking with IT
16-09-2024
What’s Next? The Future of Asteroid Tracking with IT
16-09-2024
-
 Learn AutoCAD 2D Mechanical Drawing with Our Comprehensive CAD Software Course
19-09-2024
Learn AutoCAD 2D Mechanical Drawing with Our Comprehensive CAD Software Course
19-09-2024